
Papers I Read: 2015 Week 7
Sun, Feb 15, 2015
Random Ramblings
Well, another week, another big data breach. This time is Anthem, one of the nation’s largest health insurers. Ok, maybe it was last week that it happend. But this week they revealed that hackers had access … going back as far as 2004. WSJ blamed Anthem for not encrypting the data. Though I have to agree with Rich Mogull over at Securosis that “even if Anthem had encrypted, it probably wouldn’t have helped”.
I feel bad for saying this but there’s one positive side effect from all these data breaches. Security is now officially a boardroom topic. Anthem’s CEO, Joseph Swedish, is now under the gun because top level executives are no longer immune to major security breaches that affect the company’s top line. Just ask Target’s CEO Gregg Steinhafel, or Sony’s Co-Chairwoman Amy Pascal.
Brian Krebs wrote a detailed piece analyzing the various pieces of information available relating to the Anthem hack. Quite an interesting read.
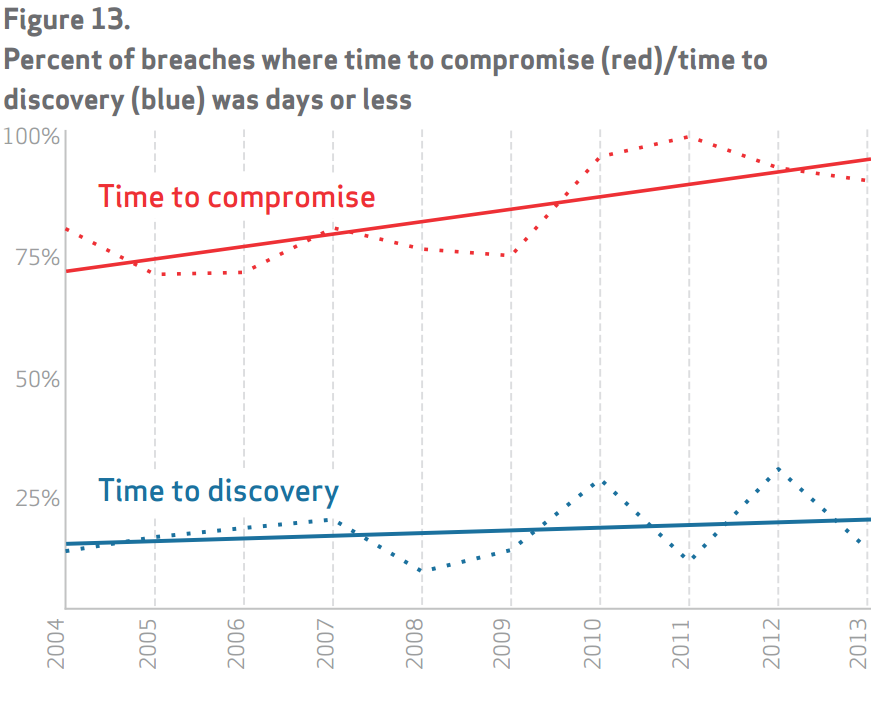
One chart in the artile that Brian referred to is the time difference between the “time to compromise” and the “time to discovery”, taken from Verizon’s 2014 Data Breach Investigations Report. As Brian summaries, “TL;DR: That gap is not improving, but instead is widening.”
What this really says is that, you will get hacked. So how do you shorten the time between getting hacked, and finding out that you are hacked so you can quickly remediate the problem before worse things happen?
With all these data breaches as backdrop, this week we also saw “President Barack Obama signed an executive order on Friday designed to spur businesses and the Federal Government to share with each other information related to cybersecurity, hacking and data breaches for the purpose of safeguarding U.S. infrastructure, economics and citizens from cyber attacks.” (Gigaom)
In general I don’t really think government mandates like this will work. The industry has to feel the pain enough that they are willing to participate, otherwise it’s just a waste of paper and ink. Facebook seems to be taking a lead in security information sharing and launched their ThreatExchange security framework this week. along with Pinterest, Tumblr, Twitter, and Yahoo. Good for them! I hope this is not a temporary PR thing, and that they keep funding and supporting the framework.
Papers I Read
Another great resource of computer science papers is Adrian Coyler’s the morning paper. He selects and summarizes “an interesting/influential/important paper from the world of CS every weekday morning”.
I read this paper when I was trying to figure out how to make the FSAs smaller for the Effective TLD matcher I created. The FSM I generated is 212,294 lines long. That’s just absolutely crazy. This paper seems to present an interesting way of compressing them.
I am not exactly sure if PublicSuffix uses a similar representation but it basically represents a FSA as an array of bytes, and then walk the bytes like a binary search tree. It’s interesting for sure.
This paper is a follow-up to Jan Daciuk’s experiments on space-efficient finite state automata representation that can be used directly for traversals in main memory [4]. We investigate several techniques of reducing the memory footprint of minimal automata, mainly exploiting the fact that transition labels and transition pointer offset values are not evenly distributed and so are suitable for compression. We achieve a size gain of around 20–30% compared to the original representation given in [4]. This result is comparable to the state-of-the-art dictionary compression techniques like the LZ-trie [12] method, but remains memory and CPU efficient during construction.
This work presents integrated model for active security response model. The proposed model introduces Active Response Mechanism (ARM) for tracing anonymous attacks in the network back to their source. This work is motivated by the increased frequency and sophistication of denial-of-service attacks and by the difficulty in tracing packets with incorrect, or “spoofed”, source addresses. This paper presents within the proposed model two tracing approaches based on: • Sleepy Watermark Tracing (SWT) for unauthorized access attacks. • Probabilistic Packet Marking (PPM) in the network for Denial of Service (DoS) and Distributed Denial of Service (DDoS) attacks.
Here we introduce the design of Dapper, Google’s production distributed systems tracing infrastructure, and describe how our design goals of low overhead, application-level transparency, and ubiquitous deployment on a very large scale system were met. Dapper shares conceptual similarities with other tracing systems, particularly Magpie [3] and X-Trace [12], but certain design choices were made that have been key to its success in our environment, such as the use of sampling and restricting the instrumentation to a rather small number of common libraries.
Not a paper, but a good write up nonetheless.
comments powered by DisqusSome people call it stream processing. Others call it Event Sourcing or CQRS. Some even call it Complex Event Processing. Sometimes, such self-important buzzwords are just smoke and mirrors, invented by companies who want to sell you stuff. But sometimes, they contain a kernel of wisdom which can really help us design better systems. In this talk, we will go in search of the wisdom behind the buzzwords. We will discuss how event streams can help make your application more scalable, more reliable and more maintainable.