
Go vs Java: Decoding Billions of Integers Per Second
Thu, Nov 14, 2013
Comments/feedbacks on reddit, hacker news
2013-11-17 Update #2: Tried another new trick. This time I updated the leading bit position function, when using the gccgo compiler, to use libgcc’s
__clzdi2routine. This had the same effect as the update #1 except it’s for when gccgo is used. Performance increase ranged from 0% to 20% for encoding only. Thanks dgryski on reddit and minux on the golang-nuts mailing list.2013-11-16 Update #1: Tried a new trick, which is to use an assembly version of bitlen to calculate the leading bit position. See the section below on “Use Some Assembly”.
So, before you crucify me for benchmarking Go vs Java, let me just say that I am not trying to discredit Go. I like Go and will use it for more projects. I am simply trying to show the results as objectively as I can, and hope that the community can help me improve my skills as well as the performance of the libraries.
I don’t consider myself a Go expert. I’ve been using Go for a few months and have been documenting the projects as I go in this blog. I’ve learned a ton and have applied many of the things I learned in optimizing this project. However, I cannot claim that I have done everything possible, so the performance numbers “could” still be better.
I would like to ask for your help, if you can spare the time, to share some of your optimization tips and secrets. I would love to make this library even faster if possible.
tl;dr
The following chart shows how much (%) faster Java is compare to Go in decoding integers that are encoded using different codecs. It shows results from processing two different files. See below for more details.
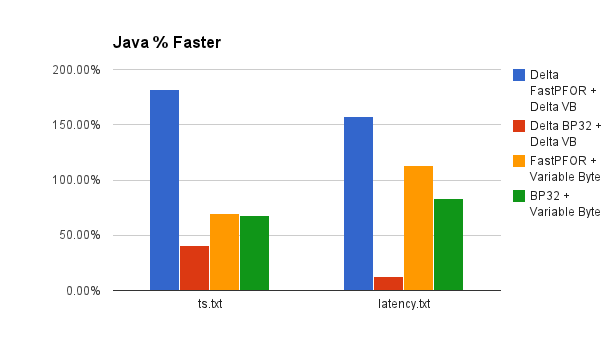
- Daniel Lemire’s Java version is anywhere from 12% to 180% faster than my Go version for decoding integers. I didn’t compare the C++ version but given that the C++ version has access to SIMD operations, it can be much faster.
- I tried many different ways to optimize my Go code for this projects, including using range for looping through slices, inlining simple functions, unrolling simple loops, unrolling even more loops, disabling bound checking (not generally recommended), using gccgo to compile, and used some assembly.
- Using gccgo -O3 resulted in the highest performance. I tested using standard gc compiler, gc -B, gccgo, and gccgo -O3. The comparison above uses the gccgo -O3 numbers.
- Using a range loop instead of unrolling a loop in one of the often used functions, AND compiling using gccgo -O3, I was able to get within 6% of Java version for Delta BP32 decoding. However, all of the other Go binaries suffered greatly.
- This benchmark is purely a CPU benchmark. The test environment has enough memory to keep all the arrays in memory without causing swap, and there’s no disk IO involved in the actual encoding/decoding functions.
Project Review
A month ago I wrote about my “Go Learn” project #6: Benchmarking Integer Compression in Go (github). In that project I ported 6 different codecs for encoding and decoding 32-bit integers. Since then, I have ported a couple more codecs, cleaned up the directories, and performed a ton of profiling and optimization to increase performance.
There are now a total of 8 codecs available:
- Binary Packing (BP32), FastPFOR, Variable Byte (varint) (top level directories)
- Standard codec that encodes/decodes the integers as they are
- Delta BP32, Delta FastPFOR (new), Delta Variable Byte (under delta/)
- Encodes/decodes the deltas of the integers
- These codecs generally produce much more compact representations if the integers are sorted
- These codecs generally perform much faster, but there are some exceptions
- ZigZag BP32, ZigZag FastPFOR (new) (under zigzag/)
- Encode/decodes the deltas of the integers, where the deltas themselves are encoded using Google’s zigzag encoding
In addition, the benchmark program under benchmark/ is provided to let users easily test different integer lists and codecs.
Techniques Tried
I cannot say this enough: benchmark, profile, optimize, rinse, repeat. Go has made testing, benchmarking, and profiling extremely simple. You owe it to yourself to optimize your code using these tools. Previously I have written about how I was able to improve the cityhash Go implementation performance by 3-16X by Go profiling.
To optimize the integer encoding library, I followed the same techniques to profile each codec, and try as much as I can to optimzie the hot spots.
Below are some of the optimizations I’ve tried. Some helped, some didn’t.
For-Range Through Slices
I learned this when Ian Taylor from Google (and others) helped me optimize one of the functions using range to loop through the slices instead of for i := 0; i < b; i++ {} loops. The for-range method can be 4-7 times faster than the other way. You can see the difference between BenchmarkOffset and BenchmarkRange here.
I also found that gccgo -O3 can do some really good optimizations with simple range loops. You can see the difference with this gist. When using gc the standard Go compiler, BenchmarkRange (31.3 ns/op) is 56% slower than BenchmarkUnrolled (13.9 ns/op). However, then reverse is true when using gccgo -O3. BenchmarkUnrolled (8.92 ns/op) is 100% slower than BenchmarkRange (4.46 ns/op).
Side note: this set of benchmarks are courtesy of DisposaBoy and Athiwat in the #go-nuts IRC channel. Thanks for your help guys.
Unroll Simple Loops
For some simple, known-size, loops, such as initializing a slice with the same initial non-zero value, unrolling the loop makes a big difference. The caveat is that gccgo -O3 does an amazing job of optimizing these simple range loops, so in that case unrolling the loop is actually slower.
As an example, the following function is unrolled as
func deltaunpack0(initoffset int32, in []int32, inpos int, out []int32, outpos int) {
out[outpos+0] = initoffset
out[outpos+1] = initoffset
out[outpos+2] = initoffset
.
.
.
It was originally written as
tmp := out[outpos:outpos+32]
for i, _ := range tmp {
tmp[i] = initoffset
}
When unrolled, AND using the standard gc compiler, we saw performance increase by almost 45% if this function is called often. However, as we mentioned above, when using gccgo -O3, the for-range loop is 33% faster than the unrolled method.
For now, I am keeping the unrolled version of the function.
Unroll Even More Loops
Given the success of unrolling the above simple loop, I thought I try unrolling even . more . loops to see if it helps.
It turns out performance actually suffered in some cases. I speculated that the reason may have to do with the bound checking when accessing slices. It turns out I might be right. After I disabled bound checking, performance increased when unrolling these loops. See below regarding disable bound checking.
Inline Simple Functions
There are several . small functions that gets called quite often in this encoding library. During profiling I see these functions being on top all the time.
I decided to try and inline these functions to see if the reduced function call overhead will help. In general I didn’t see much performance improvements using this technique. The most I saw was a 1% increase in performance. I contribute that to noise.
Disable Bound Checking (Generally NOT Recommended)
This integer encoding library operates on large slices of data. There’s a TON of slice access using index. Knowing the every slice access using index requires bound checking, I decided to try disabling bound checking using -gcflags -B to compile the code.
Disabling the bound checking for the Go compiler didn’t help as much as I hoped. For ts.txt, disabling bound checking increased performance by 10% for Delta BP32 encoding only.
However, if I disabled bound checking AND unrolled even more loops, we saw decoding performance increase anywhere from 10-40%. Encoding performance didn’t see much change. The following chart shows the performance increase (%) from the for-range loops to unrolled some additional loops when I disabled bound checking. This is comparing to the standard gc compiler.
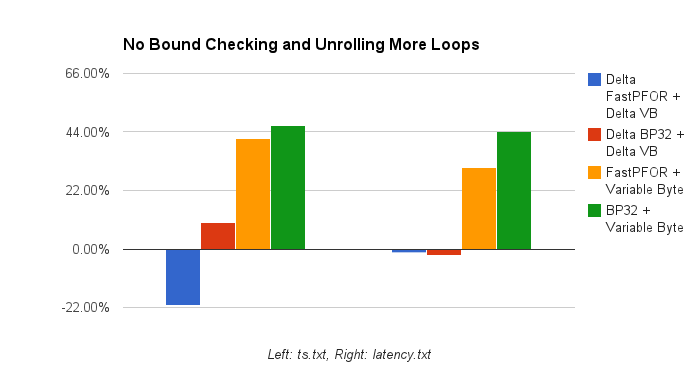
The question is, is it worth the removal of bound checking? For the raw results, I kept the numbers from the for-range loops.
Using gccgo
When I was looking around for Go optimization techniques, I saw several posts on StackOverflow as well as the Go mailing list suggesting people try gccgo as the compiler if they wanted more performance. So I thought I give it a shot as well. After downloading gcc 4.8.2 and letting it compile overnight, I was finally able to test it out.
Compiling with gccgo without any optimization flags actually saw performance drop by 50-60%. The best performance result was achieved when I compiled using gccgo -O3. The comparison to Java uses the numbers from that binary.
As mentioned above, gccgo -O3 seems to do a pretty amazing job of optimizing simple range loops. I was able to achieve 33% performance increase using for-range with gccgo -O3 instead of unrolling the simple loop. The final result was within 6% of the Java version for Delta BP32 decoding.
Use Some Assembly
The final trick I tried is to convert one of the often used functions to assembly language. This was suggested to me almost 6 weeks ago by Dave Andersen on the golang-nuts Google group. He suggested that I steal the bitLen function in the math/big/arith files. That’s exactly what I did.
The bitlen function returns the position of the most significant bit that’s set to 1. It is most often called by encoding methods to determine how many bits are required to store that integers. So natually one would expect only the encoding functions will be improved.
That’s exactly what happened. Using the new bitlen assembly function, I was able to improve encoding performance by anywhere from 3% to 40%, depending on the codec. The most significant improvement was saw when Delta FastPFOR encoding was applied on latency.txt. It consistently saw ~40% performance increase.
As such, the code has been updated to use the assembly version of the bitlen.
Benchmark Environment
The system I used to run the benchmarks was graciously provided by Dr. Daniel Lemire. Here are the CPU and memory information at the time I ran the benchmarks. As you can see, we have plenty of memory to load the large integer arrays and should cause no swap. (I had this issue running these tests on my little MBA with 4GB of memory. :)
No disk IO is involved in this benchmark.
OS
NAME="Ubuntu"
VERSION="12.10, Quantal Quetzal"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu quantal (12.10)"
VERSION_ID="12.10"
CPU
model name : Intel(R) Xeon(R) CPU E5-1620 0 @ 3.60GHz
cpu MHz : 3591.566
cache size : 10240 KB
Memory
total used free shared buffers cached
Mem: 32872068 13548960 19323108 0 209416 11517476
-/+ buffers/cache: 1822068 31050000
Swap: 33476604 0 33476604
java
java version "1.7.0_25"
OpenJDK Runtime Environment (IcedTea 2.3.10) (7u25-2.3.10-1ubuntu0.12.10.2)
OpenJDK 64-Bit Server VM (build 23.7-b01, mixed mode)
go and gccgo
go version go1.2rc4 linux/amd64
gcc version 4.8.2 (GCC)
Files
There are two files used in this benchmark:
- File 1: ts.txt contains 144285498 sorted integers. They are timestamps at 1 second precision. There are a lot of repeats as multiple events are recorded for that second.
- File 2: latency.txt contains 144285498 unsorted integers. An example, lat.txt.gz, can be seen here.
Codecs
For this benchmark, I used 4 different codecs:
- Delta Binary Packing (BP32) (Java, Go)
- Delta FastPFOR (Java, Go)
- Binary Packing (BP32) (Java, Go)
- FastPFOR (Java, Go)
Because both BP32 and FastPFOR work on 128 integer blocks, the 58 remaining integers from the test files are encoded using Delta VariableByte and Variable Byte codecs, respectively. This is achieved using a Composition (Java, Go) codec.
The Java and Go versions of the codecs are almost identical, logic-wise, aside from language differences. These codecs operate on arrays (or slices in Go) of integers. There are a lot of bitwise and shift operations, and lots of loops.
Benchmark Results
The raw results from running different Go compilers (and flags) and codes are in the Google spreadsheet at the bottom of the post.
To be consistent, all the percentage numbers presented below are based on dividing the difference between the larger number (A) and the smaller number (B) by the smaller number (B).
(A - B) / B
So you can say that A is faster than B by X%.
Go Fastest
I compiled 4 different versions of Go binary for this benchmark:
- benchmark.gc
- This is built using the standard Go compiler, gc. The command is
go build benchmark.o.
- This is built using the standard Go compiler, gc. The command is
- benchmark.gc-B
- This is built using the standard Go compiler, gc, and I turned off bound checking for this version since the codecs deals with slices a lot. The command is
go build -gcflags -B benchmark.o.
- This is built using the standard Go compiler, gc, and I turned off bound checking for this version since the codecs deals with slices a lot. The command is
- benchmark.gccgo
- This is built using the gccgo compiler with no additional flags. The command is
go build -compiler gccgo benchmark.o.
- This is built using the gccgo compiler with no additional flags. The command is
- benchmark.gccgo-O3
- This is built using the gccgo compiler with the -O3 flag. The command is
go build -compiler gccgo -gccgoflags '-O3 -static' benchmark.o.
- This is built using the gccgo compiler with the -O3 flag. The command is
Surprisingly, disabling the bound checking for the Go compiler didn’t help as much as I hoped. For ts.txt, disabling bound checking increased performance by 10-40% for encoding only. For ts.txt decoding and latency.txt, it didn’t help at all.
Using the gccgo compiler with no flags had the worst performance. In general we saw that benchmark.gc (standard Go version) is about 110%-130% faster than the gccgo version.
Lastly, the gccgo-O3 version is the fastest. This is the version that’s compiled using -O3 flag for gccgo. We saw that the gccgo-O3 version is anywhere from 10% to 60% faster than the gc version.
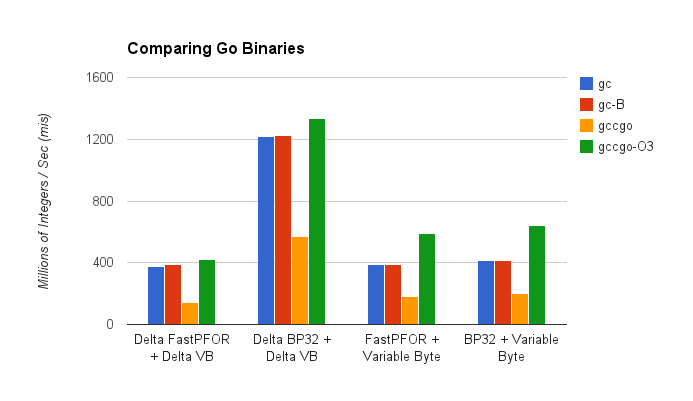
Above is a chart that shows the decoding performance of the ts.txt file for the different binaries and codecs.
For the comparison with Java, I am using the gccgo-O3 numbers.
Bits Per Integer (Lower is Better)
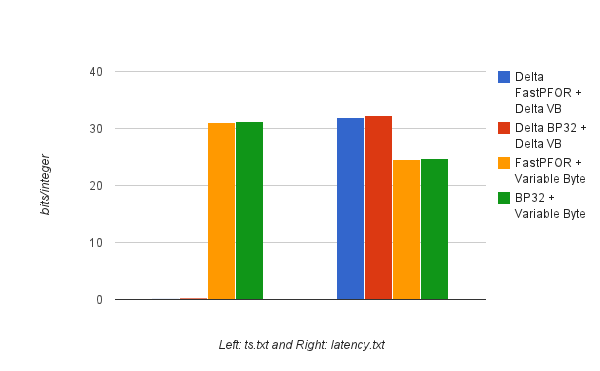
As you can tell, when the integers are sorted (ts.txt), the compression ratio is VERY good. Delta BP32 achieved 0.25 bits per 32-bit integer, and Delta FastPFOR is even better at 0.13 bits per integer. This is also because there are a lot of repeats in ts.txt.
Because the timestamps are rather large numbers, e.g., 1375228800, when the non-delta codecs are used, they did not achieve very good compression ratio. We achieved ~31 bits per 32-bit integer using standard FastPFOR and BP32 codecs.
When the integers are NOT sorted, then we run into trouble. When delta codecs are used, a lot of deltas are negative numbers, which means the MSB for most of the deltas is 1. In this case, it’s actually better to use the standard codecs instead of the delta codecs. The standard codecs achieved ~24 bits per 32-bit integer, and the delta codecs were ~32 bits per 32-bit integer.
I also tested the latency file against the zigzag delta codecs and achieved ~25 bits per 32-bit integer. So it’s not much better than the standard codecs. However, zigzag delta comes in extremely handy when the negative numbers are smaller.
Java vs. Go
For this section, we are comparing the decoding speed between the fastest Go version and Java. As you saw at the beginning of this post. Daniel Lemire’s Java version is anywhere from 12% to 180% faster than my Go version for decoding integers.
The following chart shows how much (%) faster Java is compare to Go in decoding integers that are encoded using different codecs. It shows results from processing two different files. See below for more details.
The following chart shows the decoding performance while processing ts.txt.
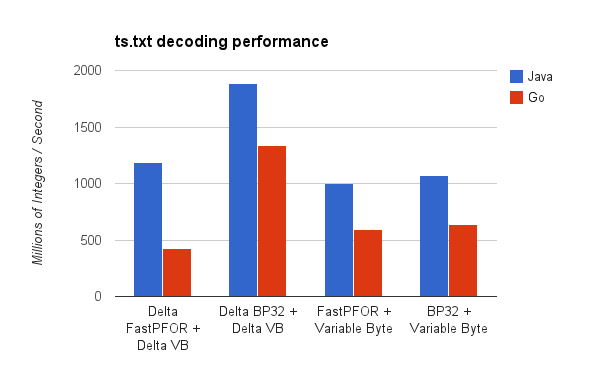
The following chart shows the decoding performance while processing latency.txt.
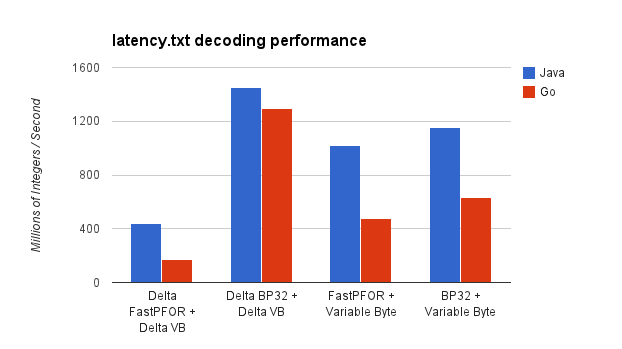
Raw Results
The raw results are in the following Google spreadsheet.
Comments/feedbacks on reddit, hacker news
comments powered by Disqus